MAGA AI Draw
MAGA AI Draw takes the best parts of Dall-E 2 and Latent Diffusion, adding its own unique components. It applies the CLIP model as both a text and image encoder and connects the CLIP modalities with a diffusion image prior mapping in the latent space.
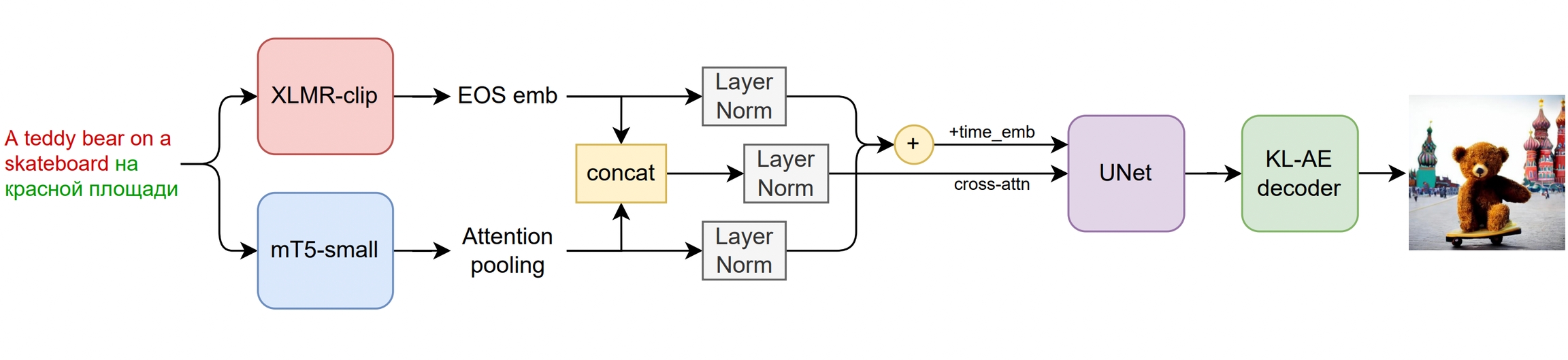
This technique improves the model's visual output and allows for combinations of images and modifications of images through text. A transformer consisting of 20 layers, 32 heads, and a hidden size of 2048 is employed to soften the latent spaces.



MAGA AI Draw is a revolutionary model which enables users to create remarkably lifelike images in an impressively short amount of time, simply using text. With this amazing technology, billions of people now have the opportunity to let their imaginations run wild and create works of art without restrictions; offering them ample opportunity to express themselves. Architecture Structures: Text Encoder: ViT-L/14 - 480M Image Prior: 1B Latent Image Encoder: CLIP (ViT-L/14) - 480M Diffusion Diffusion U-Net: 1.22B MoVQ Encoder/Decoder: 48M
Generate and enhance traditional portraits by using software with advanced capabilities like LoRA networks.
This model was designed to create traditional portraits with an authentic painting-like look, as well as stunning backgrounds and anime-style characters. To get the most out of it, using LoRA networks to generate and enhance these images is recommended.
We have set CLIP to skip 2 for all the images of version 4, and set ENSD to 31337. Furthermore, highres.fix or img2img settings have been increased to a higher resolution for all images. -- MAGA AI Draw is available at https://trump.financial/draw
Last updated